Keras Sequential 모델로 시작하기
Sequential 모델은 계층을 선형으로 쌓은 것입니다.
다음과 같이 계층 인스턴스 리스트를 생성자에 전달하여 Sequential 모델을 만들 수 있습니다:
Notice
CodeOnWeb에서는 따로 파이썬을 설치하지 않더라도 코드박스 아래의 실행 버튼을 클릭하여 바로 파이썬 코드를 실행해볼 수 있습니다. TensorFlow, Theano와 같은 백엔드 코드도 마찬가지로 설치 없이 실행 버튼만 눌러 실행할 수 있습니다. 'Keras 연습하기' 과정에서는 실행 결과까지 출력하는 예제 코드에 대해서만 실행하여 결과를 확인할 수 있도록 하였습니다.
.add() 메소드를 이용해 계층을 쉽게 추가할 수도 있습니다:
입력 형태 지정하기
모델은 어떤 형태의 입력이 들어올지 알아야 합니다. 이러한 이유로 Sequential 모델의 첫 번째 계층(이후 계층은 자동으로 모양을 추론할 수 있으므로 첫 번째 계층만 해당)에 입력 형태에 대한 정보를 제공해야 합니다. 이를 수행할 수 있는 몇 가지 방법이 있습니다:
- 첫 번째 계층에
input_shape인수를 전달합니다. 이것은 형태 정보를 담은 튜플입니다(정수 또는None을 항목으로 가지는 튜플인데,None은 임의의 양의 정수를 나타냅니다).input_shape에 batch 차원은 포함되지 않습니다. Dense와 같은 일부 2차원 계층은input_dim인수를 통해 입력 형태를 지정할 수 있으며, 일부 3차원 시간 계층(temporal layers)는input_dim과input_length인수를 지원합니다.- 입력에 대해 고정된 batch 크기를 지정하려는 경우 (이는 상태유지 재발 신경망(stateful recurrent networks)에 유용함) 계층에
batch_size인수를 전달할 수 있습니다.batch_size = 32와input_shape = (6, 8)을 한 계층에 같이 전달하면 모든 입력 batch가(32, 6, 8)의 형태를 가질 것으로 기대합니다.
따라서 다음 두 코드는 완전히 같습니다:
컴파일
모델을 학습하기 전에 compile 메소드를 통해 학습 과정을 구성해야 합니다. 이 메소드는 세 가지 인수를 받아들입니다.
- 최적화기. 기본 제공되는 최적화기(
rmsprop또는adagrad등)를 나타내는 문자열 식별자, 또는Optimizer클래스의 인스턴스가 될 수 있습니다. 최적화기를 참조하십시오. - 손실 함수(loss function). 이것은 모델이 최소화하려고 하는 대상입니다. 기본 제공되는 손실 함수의 문자열 식별자(
categorical_crossentropy또는mse등)일 수도 있고 목표 함수 자체일 수도 있습니다. 손실을 참조하십시오. - Metric의 리스트. 분류(classification) 문제를 풀고자 하는 경우
metrics = ['accuracy']로 설정하는 것이 좋습니다. 메트릭은 기본 제공되는 메트릭 또는 사용자 정의 메트릭 함수의 문자열 식별자가 될 수 있습니다.
훈련
Keras 모델은 Numpy 배열로 이루어진 입력 데이터 및 레이블을 기반으로 훈련합니다. 모델을 훈련할 때는 일반적으로 fit 함수를 사용합니다. 자세한 것은 [모델] Sequential를 참조하십시오.
예제
시작을 도와줄 몇 가지 예제를 소개합니다!
예제 폴더에는 실제 데이터셋을 바탕으로 한 모델 예제도 찾을 수 있습니다:
- CIFAR10 작은 이미지 분류 : 실시간으로 데이터가 증가하는 합성곱 신경망(Convolutional Neural Network, CNN)
- IMDB 영화 평가 정서 분류: 단어 시퀀스에 대한 LSTM
- Reuters 뉴스 서비스 주제 분류 : MLP (Multilayer Perceptron)
- MNIST 숫자 손글씨 분류: MLP & CNN
- LSTM을 이용한 문자 수준의 텍스트 생성
… 그리고 더 있습니다.
다차원(multi-class) softmax 분류를 위한 Multilayer Perceptron (MLP):
이진(binary) 분류를 위한 MLP:
VGG-like 합성곱신경망:
LSTM을 이용한 시퀀스 분류:
1차원 합성곱을 이용한 시퀀스 분류:
Stacked LSTM을 이용한 서열 분류
이 모델에서는 3개의 LSTM 계층을 쌓아 올려, 모델이 좀 더 고수준의 시간 정보를 학습하게 합니다.
첫 두 LSTM은 전체 출력 시퀀스를 반환하는 반면 마지막 LSTM은 출력 시퀀스의 마지막 단계만 반환해서 시간 차원을 삭제합니다(즉 입력 시퀀스를 하나의 벡터로 변환).
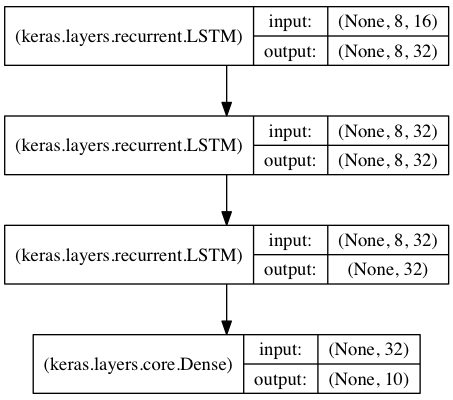
"상태"를 재사용하는 stacked LSTM 모델
상태유지 재발(Stateful recurrent) 모델은 샘플의 한 배치를 처리한 후 얻은 내부 상태(메모리)를 다음 배치 샘플의 초기값으로 다시 사용하는 모델입니다. 이렇게 하면 계산상의 복잡성을 줄이면서도 더 긴 시퀀스를 처리할 수 있습니다.
FAQ에서 stateful RNN에 관해 더 자세히 알아볼 수 있습니다.
이 문서는 Keras의 Guide to Sequential model을 번역한 것입니다.
최종 수정일: 2017년 8월 17일.
토론이 없습니다